Przedsiębiorstwa obecne na rynku od wielu lat posiadają przepastne zasoby dokumentacji formalno-prawnej składającej się m.in. z aktów notarialnych, umów dzierżawy, użyczenia, użytkowania lub najmu, umów udostępniania nieruchomości pod inwestycję i innych umów o podobnym charakterze, zawieranych między firmami, jednostkami publicznymi czy innymi podmiotami.
Z upływem czasu i w miarę rozwoju firm i zdobywania nowych klientów, te archiwa tylko się powiększają. Taka jest rzeczywistość wielu podmiotów z sektora telekomunikacji, energetyki, ciepłownictwa czy sektora wodno-kanalizacyjnego. W zależności od konkretnego przypadku, dokumentacja jest przechowywana w całości na papierze lub jest tylko częściowo zdigitalizowana i przechowywana w formie cyfrowej.

Aby móc sprawnie funkcjonować, firmy potrzebują jednak łatwego i szybkiego wglądu do danych zawartych we wspomnianych dokumentach – zarówno w sytuacjach awaryjnych, jak i do wykonywania zupełnie rutynowych zadań. Takie możliwości zapewnia baza danych, w której informacje są odpowiednio skategoryzowane i ustrukturyzowane, dzięki czemu możliwy jest szybki dostęp do konkretnej informacji, ale też do pewnego zakresu danych. Cyfrowa baza danych pozwala też na o wiele łatwiejsze analizowanie i interpretowanie danych oraz tworzenie raportów niż papierowe archiwum dokumentacji, czy proste repozytorium cyfrowe w postaci poddanych OCR skanów, w którym da się co prawda wyszukać konkretne informacje, ale w dalszym ciągu są one nieustrukturyzowane i nie ma możliwości dalszej swobodnej pracy z tymi danymi.
Tu rodzi się jednak pytanie, w jaki sposób dane trafiają z papierowych dokumentów do tych baz danych? I czy istnieje sposób na usprawnienie tej pracy?
W jaki sposób informacje z dokumentów trafiają do bazy danych?
Zwykle odpowiedź na to pytanie jest bardzo prosta i o wiele mniej spektakularna niż byśmy oczekiwali.
Wprowadzaniem danych zajmuje się osoba, często zatrudniona specjalnie do tego celu, która wypisuje kluczowe informacje z dokumentów i wprowadza je ręcznie do odpowiednich rubryk w bazie danych. Najczęściej są to informacje takie jak: data zawarcia umowy, numer umowy, rodzaj umowy, numer repertorium, numer księgi wieczystej. Dzięki temu z informacji zawartych w dokumentacji formalno-prawnej może swobodnie korzystać wiele działów w firmie – na przykład dział obsługi klienta, co rzecz jasna znacznie usprawnia pracę.

O ile mamy do czynienia z małą liczbą dokumentów, a uzupełnianie bazy danych nie zajmuje dużej części dnia pracy, zadanie to nie stanowi wielkiego wyzwania, chociaż bez wątpienia jest bardzo powtarzalne i nużące. Zwykle jednak, zwłaszcza w dużych firmach o długiej tradycji, mamy do czynienia z bardzo dużą ilością dokumentów i danych, które trzeba wprowadzić i których ciągle przybywa. W praktyce praca ta może zająć nawet ¾ czy pełny etat. Tak więc firma musi zatrudnić osobę, której jedynym zadaniem jest przepisywanie danych z dokumentów do bazy danych i czuwanie nad ich poprawnością.
Ręczne wprowadzanie danych rodzi szereg problemów:
Jak usprawnić pozyskiwanie informacji z papierowej dokumentacji formalno-prawnej?
Ponieważ Globema działa w sektorze badawczo-rozwojowym, postanowiliśmy przyjrzeć się temu problemowi z bliska i podjąć wyzwanie znalezienia lepszego sposób na pozyskiwanie danych z dokumentów, i usunięcie tego wąskiego gardła w pracy wielu przedsiębiorstw.
Odpowiedzią było wykorzystanie algorytmów AI/ML i automatyzacja procesu. Sięgnęliśmy do naszych doświadczeń z aplikacją LocDoc i wykorzystaniem sztucznej inteligencji do kategoryzacji dokumentów i sczytywania danych z powykonawczej dokumentacji technicznej.
Zastosowaliśmy podobne mechanizmy AI/ML jak w rozwiązaniu LocDoc – tym razem do automatyzacji czytania i wprowadzania danych z dokumentacji formalno-prawnej do baz danych działających już w przedsiębiorstwie. Tak powstał iDoc.
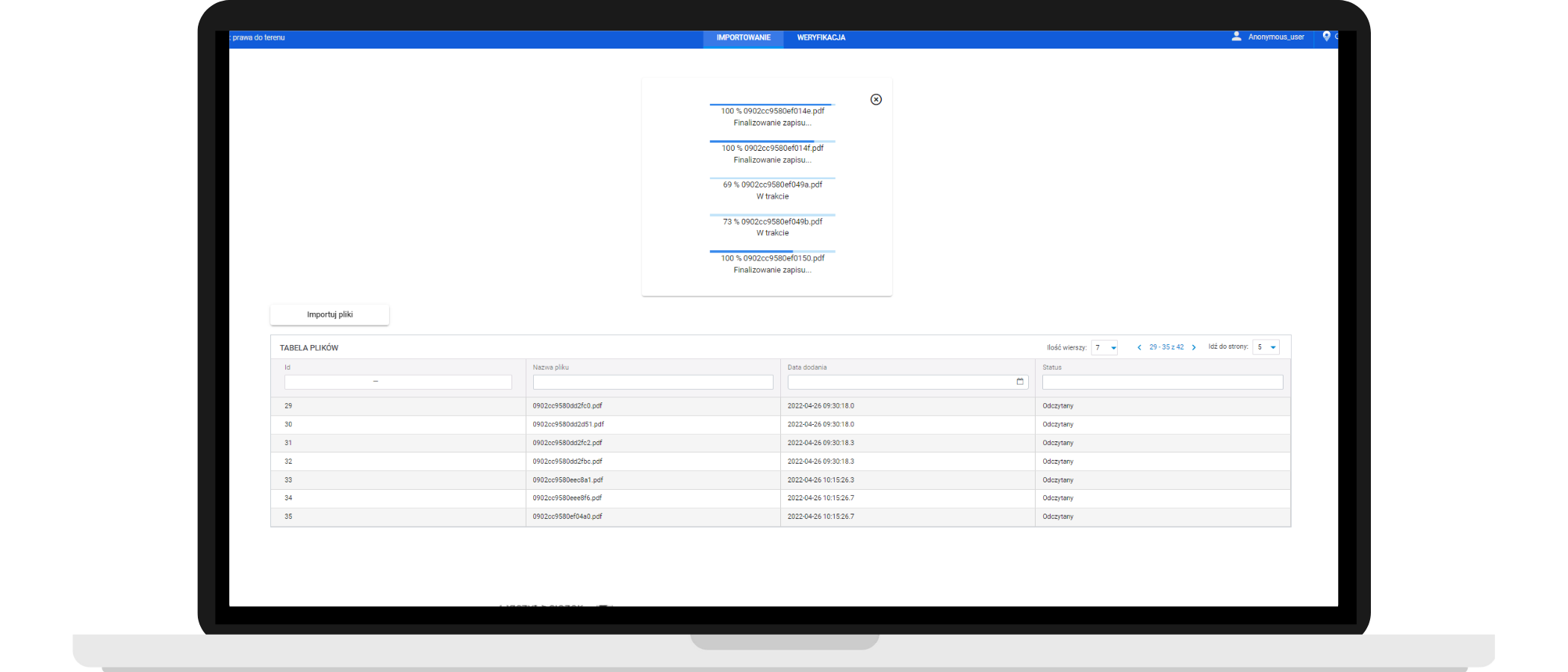
Kliknij, aby powiększyć
Aplikacja iDoc. Ładowanie zeskanowanych dokumentów do systemu – przygotowanie do sczytywania i kategoryzacji danych.
Jak działa rozwiązanie iDoc do automatycznego sczytywania i kategoryzacji danych?
Rozwiązanie iDoc wykorzystuje algorytmy sztucznej inteligencji, AI/ML, do automatycznego sczytywania i kategoryzacji danych zawartych w dokumentach formalno-prawnych.
iDoc rozumie i poprawnie czyta dokumentację formalno-prawną:
- akty notarialne,
- umowy dzierżawy,
- umowy najmu
a także inne umowy o podobnym charakterze, zawierane pomiędzy firmami oraz firmami i jednostkami publicznymi czy innymi podmiotami. Każdy z wymienionych rodzajów umowy jest inny i zawiera szereg typowych dla siebie informacji – inne informacje będzie zawierać akt notarialny, inne umowa najmu.
Algorytm czyta informacje zawarte w dokumencie, rozpoznaje jaki to dokument (kategoryzuje go), następnie, zbiera zawarte w nim informacje i zapisuje je we własnej bazie danych (zgodnie z kategorią dokumentu i rodzajem danych – atrybutami, przypisanymi do każdej z kategorii). Ta baza danych może być następnie zintegrowana z bazami danych lub systemami działającymi już w firmie.
Zakres sczytywanych informacji zawartych w umowach, jest bardzo szeroki, jest to około 30-40 różnych atrybutów – kategorii informacji, w zależności od rodzaju umowy, m.in.:
- dane o stronach umowy (nazwy firm, właściciele, kontrahenci, pełnomocnicy, notariusz)
- dane adresowe (adresy wszystkich stron, numery działek, obrębów),
- okresy obowiązywania umowy,
- daty podpisania umowy,
- numery identyfikujące umowy jak np. nr księgi wieczystej,
- szczegóły obiektów,
- informacje o przedmiocie zawartej umowy,
- informacje o płatnościach.

Przetworzenie jednego aktu notarialnego (odczytanie, skategoryzowanie danych i umieszczenie ich w bazie danych) zajmuje aplikacji iDoc kilkanaście sekund, co jest wynikiem nieosiągalnym przez człowieka (tutaj średnia to około 11 minut na 6 stronicowy dokument).
Sprawne pozyskanie informacji o służebności z dokumentów z pomocą AI
Zobacz, jak dzięki wykorzystaniu AI do odczytywania danych, Stoen Operator skrócił czas przeznaczony na archiwizację umów o służebności i aktów notarialnych o ponad 60%.
Czy sztuczna inteligencja wykona całą pracę i zastąpi człowieka?
Rozwiązanie Globemy bazujące na algorytmach sztucznej inteligencji czyta i interpretuje dane z dokumentów, nadal jednak przy wprowadzaniu danych do systemu potrzebny jest udział człowieka. Po pierwsze musi on załadować do rozwiązania zeskanowane dokumenty (iDoc nie skanuje dokumentów – sczytuje i kategoryzuje informacje z dokumentów już zeskanowanych), ale co najważniejsze, musi zweryfikować poprawności danych odczytanych przez algorytm, zwracając szczególną uwagę na miejsca, które są trudne do odczytania przez automat. Do takich można zaliczyć: pismo ręczne, pieczątki, niewyraźny skan, zagięcia, ubytki w papierze lub tuszu, czy zagmatwaną logikę, gdy np. atrybuty są wyliczane na podstawie pośrednich informacji.
Jak wygląda proces weryfikacji? Każdy dokument jest pokazany na ekranie z zaznaczonymi na nim sczytanymi frazami a obok znajduje się panel z oknami wypełnionymi tymi właśnie danymi. Wszystkie sczytane obiekty i atrybuty są w panelu ułożone w logicznym porządku z przypisanymi kolorami współgrającymi z zaznaczonymi frazami na stronach. Taki „kod kolorów” pozwala użytkownikowi na szybką, wizualną weryfikację poprawności poprzez porównywanie danych pomiędzy dwoma oknami – dokumentu i panelu.
Na koniec trzeba jeszcze wprowadzić niezbędne poprawki i zaakceptować zweryfikowany dokument.
Jak widać ludzka praca nie jest eliminowana z całego procesu. Człowiek nadal pełni w nim ważną rolę – może nawet istotniejszą niż wcześniej. Zamiast zajmować się, dość mechanicznym, przepisywaniem informacji, może teraz skoncentrować się na ich weryfikacji oraz zarządzaniu całym procesem aktualizacji bazy danych i zapewnienia jakości danych.
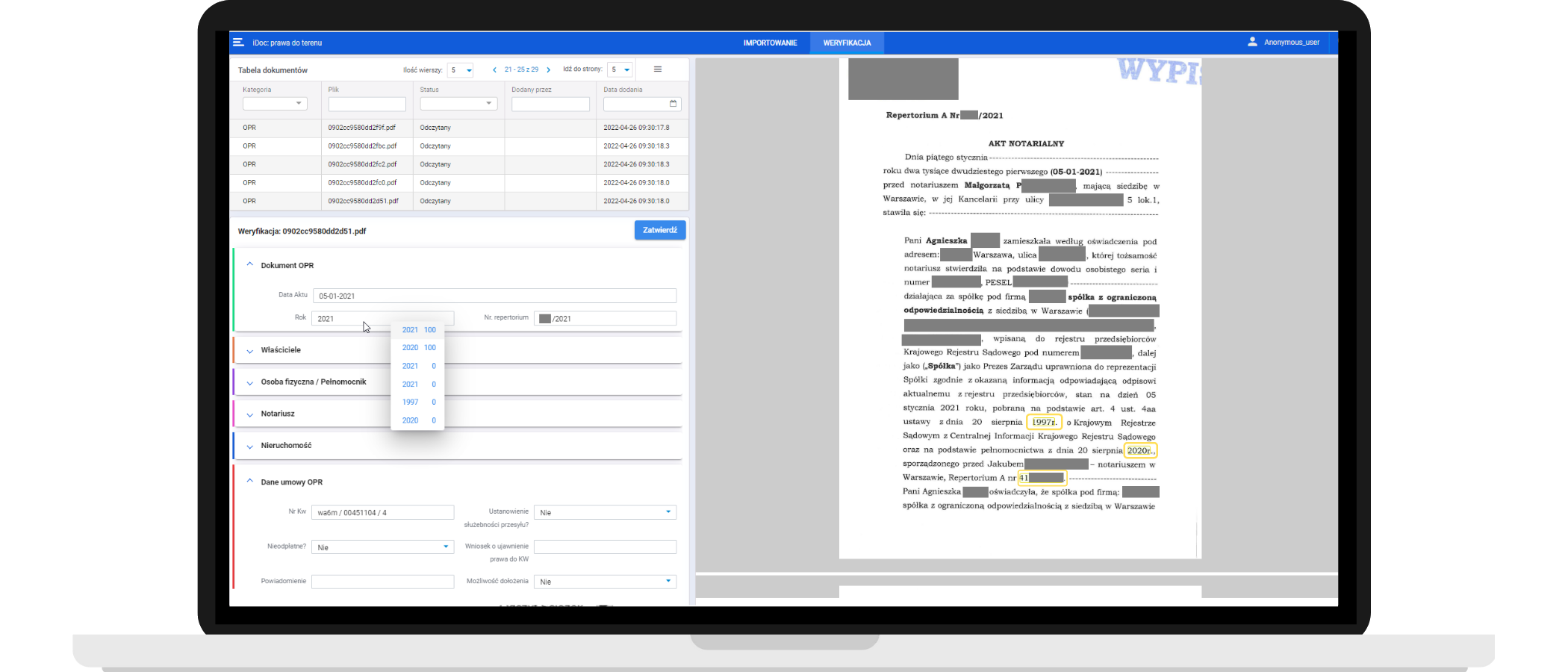
Kliknij, aby powiększyć
Aplikacja iDoc. Panel weryfikacji danych. Można w nim w łatwy sposób sprawdzić poprawność sczytanych informacji (umieszczone w oknie po lewej) i porównać ze źródłem na podglądzie dokumentu (po prawej). Aplikacja daje też do wyboru zapasowych kandydatów dla wartości danego atrybutu i zakreśla je na kolorowo na podglądzie.
Jak wygląda proces sczytywania i kategoryzacji danych w liczbach?
Przeciętnie człowiek jest w stanie skategoryzować (rozpoznać, z jakim dokumentem ma do czynienia) około 3100 stron w ciągu dnia pracy. W tym samym czasie algorytm sztucznej inteligencji skategoryzuje powyżej 30 000 stron przy dokładności minimum 96%.
Podobnie jest z odczytywaniem i umieszczaniem w bazie poszczególnych danych. W ciągu dnia pracy, człowiek jest w stanie odczytać z dokumentu i przepisać do bazy około 2000 atrybutów, natomiast automat opracuje około 10 razy tyle danych (czyli około 20 000!) przy dokładności około 85%.

Oznacza to, że, pomimo tego, że znacznie przyspieszają pracę, algorytmy nie są w stanie zapewnić 100% poprawności sczytanych danych. Mała cześć informacji, która przez model została odczytana, ale oceniona na mniej wiarygodną, zostaje podana użytkownikowi do weryfikacji. Dlatego precyzję identyfikacji atrybutów określamy jako stosunek wszystkich poprawnie sczytanych wartości atrybutów (tych, które nie wymagały poprawy przez użytkownika) do sumy wszystkich atrybutów wypełnionych przez algorytmy.
Jakie korzyści przynosi zastosowanie AI/ML w kategoryzacji dokumentów?
Jeśli wprowadzania danych z dokumentów do systemu to jedno z rutynowych działań w Twojej firmie, które pochłania cały etat, lub większą jego część, a dokumentacja stale się powiększa, trudno przecenić korzyści wynikające z automatyzacji tego procesu.
Wykorzystanie AI/ML i automatyzacja procesu wprowadzania danych z dokumentacji formalno-prawnej do bazy danych oznacza:
- od 5-10 razy szybsze kategoryzowanie i przetwarzanie danych z dokumentów
- przeniesienie żmudnej i powtarzalnej czynności na automat i skierowanie uwagi pracownika na zarządzanie procesem
- że nie ma potrzeby zatrudniania osoby wyłącznie do uzupełniania baz danych, a to przekłada się na ograniczenie kosztów rekrutacji i utrzymania pełnego etatu osoby wprowadzającej dane.
- że proces cyfryzacji dokumentów może być prowadzony poza godzinami pracy – np. w nocy i bez przerw.
- wyższą jakość danych; zautomatyzowany proces nie jest podatny na zmęczenie człowieka, rozproszenie uwagi i wynikające z tego błędy we wprowadzanych informacjach.
- bardziej kompletne bazy danych. Szansa, że ostatecznie wszystkie (również historyczne) dane znajdą się w systemie jest o wiele większa niż przy ręcznym uzupełnianiu danych.
Jeśli zastanawiasz się, czy automatyzacja przetwarzania danych z dokumentacji i rozwiązanie iDoc są odpowiednie dla Ciebie…