Wiele przedsiębiorstw boryka się z problemem ogromnej ilości nieuporządkowanej dokumentacji, często zalegającej w archiwach. Pierwszym krokiem do uporządkowania takiego stanu rzeczy jest właściwa kategoryzacja każdego dokumentu. Na przykład dokumenty księgowe można by podzielić na: umowy, faktury, protokoły odbioru, polecenia księgowania. Z kolei dokumentację techniczną o sieci na: mapy projektowe, protokoły odbioru sieci, operaty geodezyjne, protokoły awarii na sieci, protokoły awarii na stacji, karty przeglądu technicznego itp. Wprowadzenie porządku do nieuporządkowanego archiwum jest bardzo czasochłonne (i kosztowne) oraz frustrujące dla pracowników.
Dobrym rozwiązaniem mogą tu być narzędzia do automatycznej kategoryzacji dokumentów (klasyfikacji tekstu) wykorzystujące sztuczną inteligencję. Poniżej prezentujemy opis procesu automatycznej klasyfikacji oraz wyniki jednego z naszych eksperymentów z uczeniem maszynowym, przeprowadzonego w ramach projektu GlobIQ.
Klasyfikację tekstu można podzielić na następujące etapy:
Konstrukcja modelu w oparciu o zbiór danych wejściowych (przykłady uczące). Przykładowe modele (klasyfikatory) to: drzewa decyzyjne, reguły (IF .. THEN ..), sieci neuronowe. Do budowy klasyfikatora możemy wykorzystać podejście empiryczne na zasadzie „ucz się i testuj”, pozwalające na wybór optymalnego modelu dla zadanego zbioru wejściowego.
W przypadku klasyfikacji tekstu ważnym krokiem jest filtracja wyrazów o niskiej wadze informacyjnej oraz indeksowanie tekstu w celu uzyskania odpowiedniej postaci reprezentujących je wektorów. Do wykonania tych zadań można posłużyć się standardowymi bibliotekami naukowymi, np. scikit-learn.
Dokładność modelu może być weryfikowana w następujący sposób: dla przykładów testowych, dla których znane są wartości atrybutu decyzyjnego, wartości te są porównywane z wartościami atrybutu decyzyjnego generowanymi dla tych przykładów przez klasyfikator.
Miarą, która weryfikuje poprawność modelu, jest np. współczynnik dokładności. Współczynnik dokładności modelu jest liczony jako procent przykładów testowych poprawnie zaklasyfikowanych przez model. Jeśli dokładność modelu jest akceptowalna, model może być użyty do klasyfikacji przyszłych danych i przewidywania wartości nowych krotek, dla których wartość atrybutu decyzyjnego jest nieznana.
Do porównania różnych klasyfikatorów podczas klasyfikacji wieloetykietowej można użyć np. tablicy pomyłek.
Ocena na zbiorze uczącym nie jest wiarygodna jeśli rozważamy predykcję na nowych danych — nowe obserwacje najprawdopodobniej nie będą takie same jak dane uczące.
Eksperymentujemy z klasyfikacją
Poniżej prezentujemy wyniki jednego z naszych eksperymentów z uczeniem maszynowym, który został wykonany w ramach prac nad projektem GlobIQ. Doświadczenie polegało na zastosowaniu naiwnego klasyfikatora bayesowskiego w trybie uczenia z nadzorem do klasyfikacji dokumentacji projektowej.
Dodajmy jeszcze, że nadzorowana kategoryzacja tekstu polega na automatycznym przydziale tekstu do zbioru predefiniowanych klas, zwanych też kategoriami. Dany dokument może należeć do jednej klasy (zagadnienie klasyfikacji jednoetykietowej) lub wielu klas (zagadnienie klasyfikacji wieloetykietowej), zależnie od subiektywnej oceny zbioru. Odmianą klasyfikacji jednoetykietowej, jest tzw. klasyfikacja binarna, w której każdy dokument przypisuje się do zbioru lub jego dopełnienia.
Nasze działania wyglądały następująco:
- 1. Najpierw pozyskaliśmy zbiór otagowanych dokumentów projektowych składających się z plików JPG (zaszytych w PDF) podzielonych na 5 różnych kategorii. Pliki JPG zawierały skany papierowej dokumentacji, która byłą częściowo zapisana odręcznie, a częściowo zadrukowana. Liczebność zbioru wynosiła kilka tysięcy dokumentów jedno lub kilkustronicowych.
- 2. Następnie losowo wyznaczyliśmy podzbiór dokumentów, który został wykorzystany jako zbiór uczący. Liczebność zbioru uczącego wynosiła 470 dokumentów.
- 3. Użyliśmy OCR (Google Vision API Beta) do przetworzenia zbioru uczącego (plików JPG) na czysty tekst.
- 4. Za pomocą prostych funkcji oczyściliśmy tekst ze zbędnych znaków, interpunkcji, ustawienia małych liter itd.
- 5. Kolejny krok to ewaluacja różnych klasyfikatorów dla danych ze zbioru uczącego.
Podoba Ci się ten artykuł? Chcesz dostawać świeże newsy prosto na Twoją skrzynkę?
Dołącz do newslettera Globemy
i bądź zawsze na bieżąco!

- Random Forest Classifier – Lasy losowe
- Linear Support Vector Classification – Maszyna wektorów nośnych
- Multinomial Naive Bayes Classifier – Wielomianowy naiwny klasyfikator bayesowski
- Logistic Regression – Klasyfikacja za pomocą regresji logistycznej
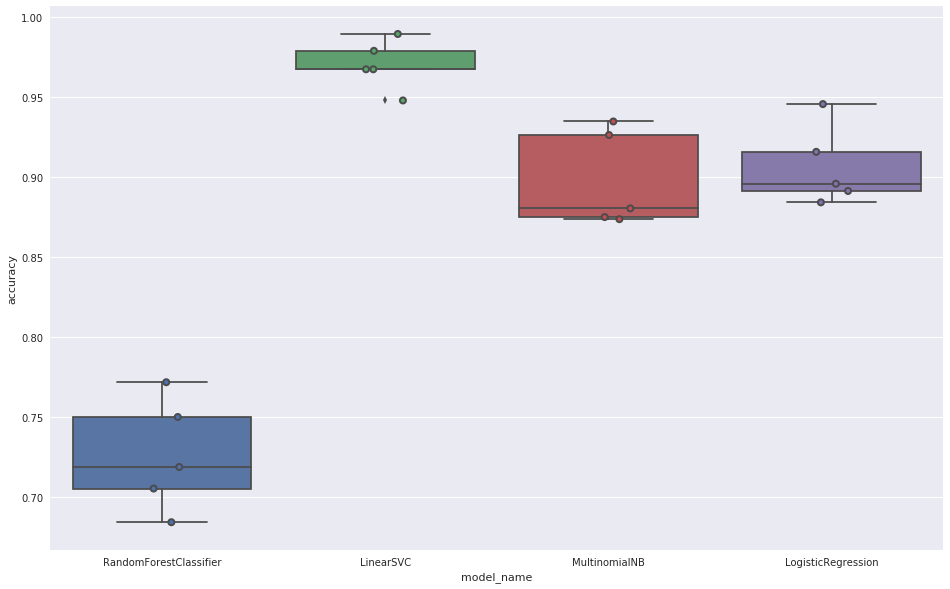
Do ewaluacji klasyfikatorów wykorzystaliśmy ten sam zbiór uczący (automatycznie podzielony na podzbiór treningowy i podzbiór testowy) 470 dokumentów ze znaną kategorią. Jako podstawowy miernik wydajności klasyfikatorów użyliśmy parametru dokładność (accuracy). Parametr ten to stosunek ilości poprawnie przewidzianych wartości do łącznej liczby wartości w zbiorze testowym.
Wyniki dla poszczególnych klasyfikatorów przedstawiały się następująco:
Najlepszy wynik (rzędu 0,975) osiągnął klasyfikator wykorzystujący maszynę wektorów nośnych (LinearSVC) i został użyty w dalszej części eksperymentu.
Dla znalezionego najlepszego klasyfikatora (LinearSVC) wykonaliśmy próbę symulacji produkcyjnej klasyfikacji dokumentów PDF ze skanami na zbiorze 6,272 dokumentów (około 24,000 stron A4). Przepływ pracy wyglądał tak:
- ekstrakcja plików JPG z plików PDF
- użycie OCR i uzyskanie czystego tekstu z pliku JPG
- użycie klasyfikatora i predykcja kategorii dokumentu
- porównanie predykcji kategorii z kategorią ustaloną przez operatora (prawdziwą).
Wyniki eksperymentu
| Kategoria | Dokumentów w kategorii | Złe predykcje | Dokładność | Uwagi |
| 1 | 2,050 | 329 | 84.0% | Niska jakość skanów |
| 2 | 342 | 1 | 99.7% | |
| 3 | 2,340 | 13 | 99.4% | |
| 4 | 0 | 0 | - | Brak dokumentów w zbiorze produkcyjnym |
| 5 | 1,539 | 13 | 99.2% | |
| Suma | 6,272 | 357 | - |
Wnioski
Osiągnęliśmy bardzo wysoką trafność kategoryzacji dokumentów – dla 3 kategorii powyżej 99%, a tylko dla jednej na poziomie 84%. Czas wykonania klasyfikacji dużej partii dokumentów (10,000 – 20,000) jest liczony w minutach.
Szacujemy, że ręczne przejrzenie i zaklasyfikowanie 10,000 dokumentów zajęłoby około 10-20 dni. Wynik eksperymentu dowodzi więc, że użycie metod sztucznej inteligencji do rozpoznawania rodzaju dokumentów jest jak najbardziej celowe.
Chcesz osiągnąć podobne wyniki?
Skontaktuj się z nami, aby porozmawiać o wykorzystaniu sztucznej inteligencji i uczenia maszynowego w Twoim biznesie.